
Exploring Dynamic Sink Routing in Apache Flink via DemultiplexingSink

Last year, I wrote a blog post discussing ideas on how to support use-cases in Apache Flink that required dynamically resolving (and potentially creating) sinks at runtime based on the incoming data. While this solution was fairly practical, it was written against older APIs as opposed leveraging the new Unified Sink API. Revisiting this lead me down a rabbit-hole, and an almost four year old JIRA ticket I created, to hopefully create a better way for handling this.
This post goes through the process of designing this, extending from the original concepts of the last post (and some attempts at a more targeted version of this implementation).
Introducing DemultiplexingSink
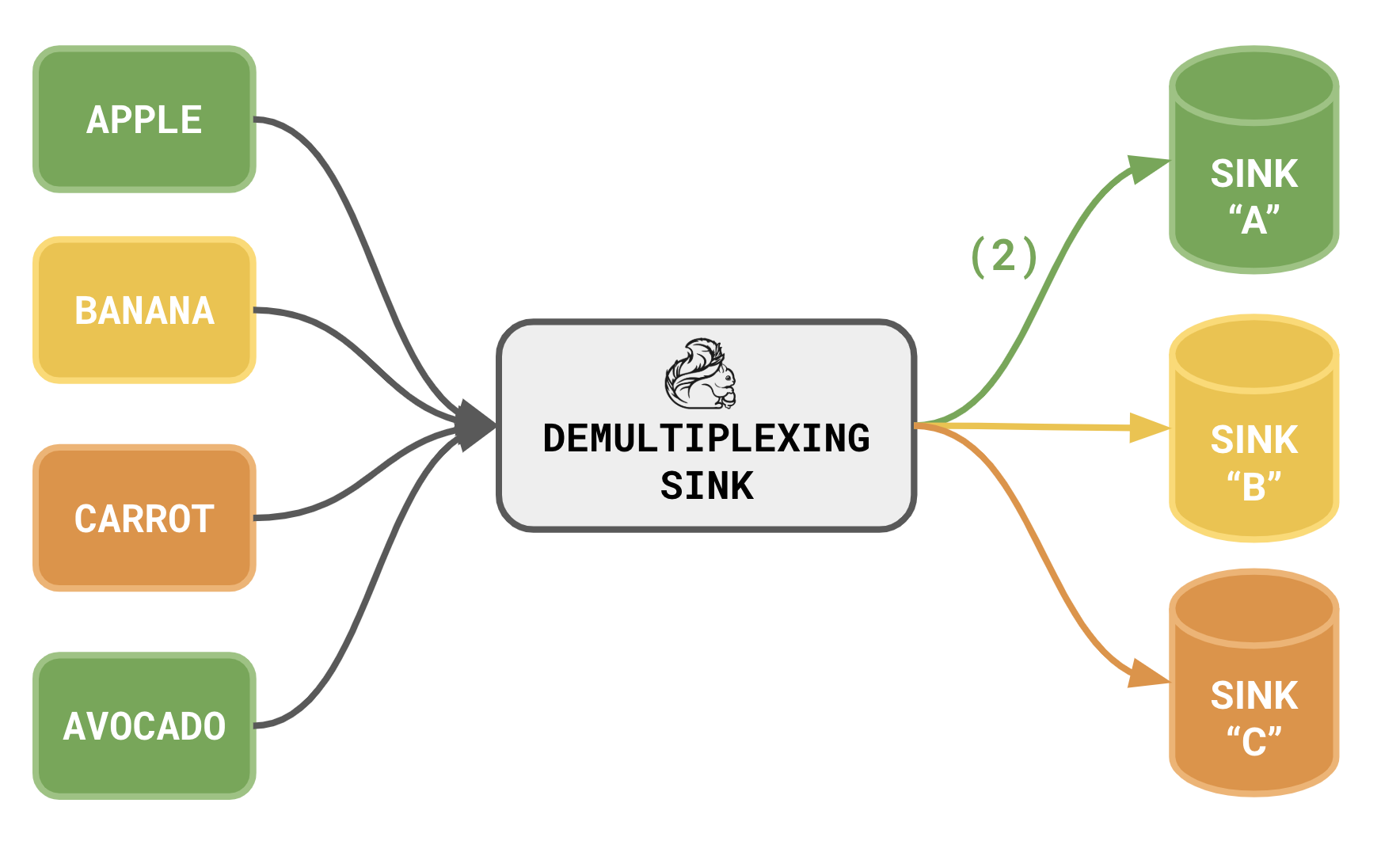
The DemultiplexingSink is a proposal to introduce a new Sink interface that supports the dynamically creation and routing to different sinks based on characteristics found within the data itself.
Quite often supporting this behavior would require compile-time knowledge of the sinks that were available. This sink changes that by allowing the relationship between an element and its destination sink to be defined through a delegate. Let's talk through the reasoning behind this and review over a few examples.
Why?
If it ain't broke, don't fix it right? That's generally the rule of thumb that I aim to live by, however there are some caveats where that mindset may start to fall apart.
A few reasons behind this could probably be lumped into the following improvements over the original implementation:
- Outdated APIs - The previous approach were using the older sink APIs as opposed to the newer Unified Sink APIs. Since I was already looking into making changes for those, revisiting this generic approach could be a good idea.
- Flexibility - The previous implementation was tailor-made to support routing to dynamic Elasticsearch-based sinks as opposed to being sink-agnostic.
- Improved State Handling and Recovery - Another area that was lacking with the previous implementation did quite a bit of hand-waving when it came to resiliency, specifically around snapshotting and state recovery.
The tl;dr; here is that I was really just following the Boy Scout Rule. I was in the area, did some reflection on what I've learned since the original implementation, and thought I could hopefully design something useful others could use.
How does it work?
The DemultiplexingSink itself is actually very simple in terms of the implementation and usage and stays true to the original implementation with a sink and a dynamic, delegate-based router.
Consider the following example use-case which resolves the Kafka topic within a given message and routes the message to that topic dynamically:
// Define SinkRouter (for routing element to specific sink)
SinkRouter<YourElement, String> router = new SinkRouter<YourElement, String>() {
@Override
public String getRoute(YourElement element) {
// Sink-key resolution (in this case get the name of the topic)
return element.getTopicName();
}
@Override
public Sink<YourElement> createSink(String topicName, YourElement element) {
return KafkaSink.<YourElement>builder()
.setBootstrapServers(...)
.setRecordSerializer(...)
.setTopics(topicName)
.build();
}
};
// Define the sink
DemultiplexingSink<YourElement, String> demuxSink =
new DemultiplexingSink<>(router);
// Example applying the sink
streamEnv
.process(YourBusinessLogic())
.sinkTo(demuxSink);This example demonstrates consuming a series of YourElement elements and routes them to dynamic Kafka topics based on a specific attribute within the object itself through the following chain of events:
- Defining the
SinkRouterinstance responsible for defining the logic to route the element to its destination topic (in this case a predefinedelement.getTopicName()implementation) - Defining a
DemultiplexingSink<YourElement, String>instance that uses the previously definedSinkRouterinstance. - When the element is sent to the sink, the logic within
SinkRouter.getRoute()will be executed to determine the sink to route the element to.- If the route key does not exist, the sink will be initialized and stored within the internal cache.
- If the key exists, the sink will be read from the cache directly.
- The element will be sent to the resolved sink.
More Examples
While the above Kafka example was pretty trivial – let's take a look at a few more commonly used sinks.
File Backend
This example routes a series of elements to files that were associated based on the lexicographical order (i.e the first character of each letter):
streamEnv
.fromData("this", "is", "a", "file", "routing", "example")
.sinkTo(
new DemultiplexingSink<>(
new SinkRouter<String, Character>() {
@Override
public Character getRoute(String element) {
return element.charAt(0);
}
@Override
public Sink<String> createSink(Character route, String element) {
// Define where and how you would want to write your files here
Path routePath = new Path("your-output-location/" + route);
// Barebones streaming file sink for your route
return FileSink
.forRowFormat(routePath, new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(15))
.withInactivityInterval(Duration.ofMinutes(5))
.withMaxPartSize(MemorySize.ofMebiBytes(128)
)
.build()
)
.build();
}
}
)
);Elasticsearch
This example routes a series of elements based on a prefixed character to indicate the Elasticsearch index to be written to:
streamEnv
.fromData("a:this", "a:is", "b:a", "c:file", "b:routing", "a:example")
.sinkTo(
new DemultiplexingSink<>(
new SinkRouter<String, String>() {
@Override
public String getRoute(String element) {
return element.split(":")[0];
}
@Override
public Sink<String> createSink(String indexName, String element) {
return new TestElasticsearchSink(
"http://your-elasticsearch:9200",
indexName
);
}
}
)
);JDBC (Postgres)
This example routes a series of elements based on a prefixed character to indicate the table to be written to:
streamEnv
.fromData("a:this", "a:is", "b:a", "c:file", "b:routing", "a:example")
.sinkTo(
new DemultiplexingSink<>(
new SinkRouter<String, String>() {
@Override
public String getRoute(String element) {
return element.split(":")[0];
}
@Override
public Sink<String> createSink(String route, String element) {
return new SampleJdbcSink(
"your-jdbc-url",
"your-username",
"your-password",
route
);
}
}
)
);
// Sample Sink
private record SampleJdbcSink(
String jdbcUrl,
String username,
String password,
String tableName
) implements Sink<String>, Serializable {
/** Omitted for brevity (see examples repo) */
}Kafka
This example routes a series of elements based on a prefixed character to indicate the Kafka topic to be written to:
streamEnv
.fromData("a:this", "a:is", "b:a", "c:file", "b:routing", "a:example")
.sinkTo(
new DemultiplexingSink<>(
new SinkRouter<String, String>() {
@Override
public String getRoute(String element) {
return element.split(":")[0];
}
@Override
public Sink<String> createSink(String topicName, String element) {
return KafkaSink.<String>builder()
.setBootstrapServers("your-bootstrap-servers")
.setRecordSerializer(
KafkaRecordSerializationSchema.<String>builder()
.setTopic(topicName)
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.build();
}
}
)
);You can see a repository with examples of all of these here complete with runnable TestContainers-based integration tests.
What's Next?
I've been playing around with the overall implementation quite a bit within this related pull request draft, however since it is a rather large change that would introduce new interfaces – a formal FLIP would be required to introduce it into Flink itself (any type of vouching would be welcome, I'm happy to do as much heavy-lifting to help the effort).
I’d love to gauge the community’s interest in this effort. In the worst case, you could simply clone or copy and paste the relevant classes to fit your needs — and in the best case, it might be as easy as a single import statement.