
Surviving the Streaming Dungeon with Kafka Queues

Recently, I’ve been borderline addicted to Matt Dinniman’s Dungeon Crawler Carl series, which I cannot recommend enough. The books drop their characters into massive, chaotic dungeons filled with monsters, traps, loot, and a deeply unhinged AI that seems determined to keep things interesting.
If you’re wondering what this has to do with Apache Kafka — nothing, just click this affiliate link and ... just kidding, I’m getting there.
Kafka systems can feel very similar. At scale, events of every shape and size are constantly flying through your infrastructure: user actions, state changes, retries, alerts, logs, background jobs. Some of them matter, most don’t. And yet, they all arrive in the same endless stream.
Priority and triage are crucial in these types of environments. Trying to treat everything as equally important is a great way to get paged at 2am. If you are in our friend Carl’s world, it’s a great way to get killed.
Survival, in Kafka and imaginary dungeons, depends on knowing what deserves attention — and making sure the right person handles it.
That’s where Kafka Queues come in.
The Importance of Party
In Dungeon Crawler Carl, the dungeon isn’t always dangerous because of any single monster or trap. It's typically because there are always multiple threats, multiple opportunities, and multiple ways things can go wrong — often all at the same time.

Carl, Princess Donut, and Mongo — collectively known as the Royal Court of Princess Donut — along with the rest of the dungeon’s crawlers, don’t survive by reacting to every single thing they see. They survive by dividing responsibility and game-planning. Someone focuses on the immediate threat. Someone else keeps an eye on positioning. Another watches for other uncertain threats.
They trust each other to handle their part to survive, just like any real engineering team or system. If everyone jumps at the first threat, they die. If no one takes ownership, they also die. If one of the threats goes unchecked or ignored — yup, dead.
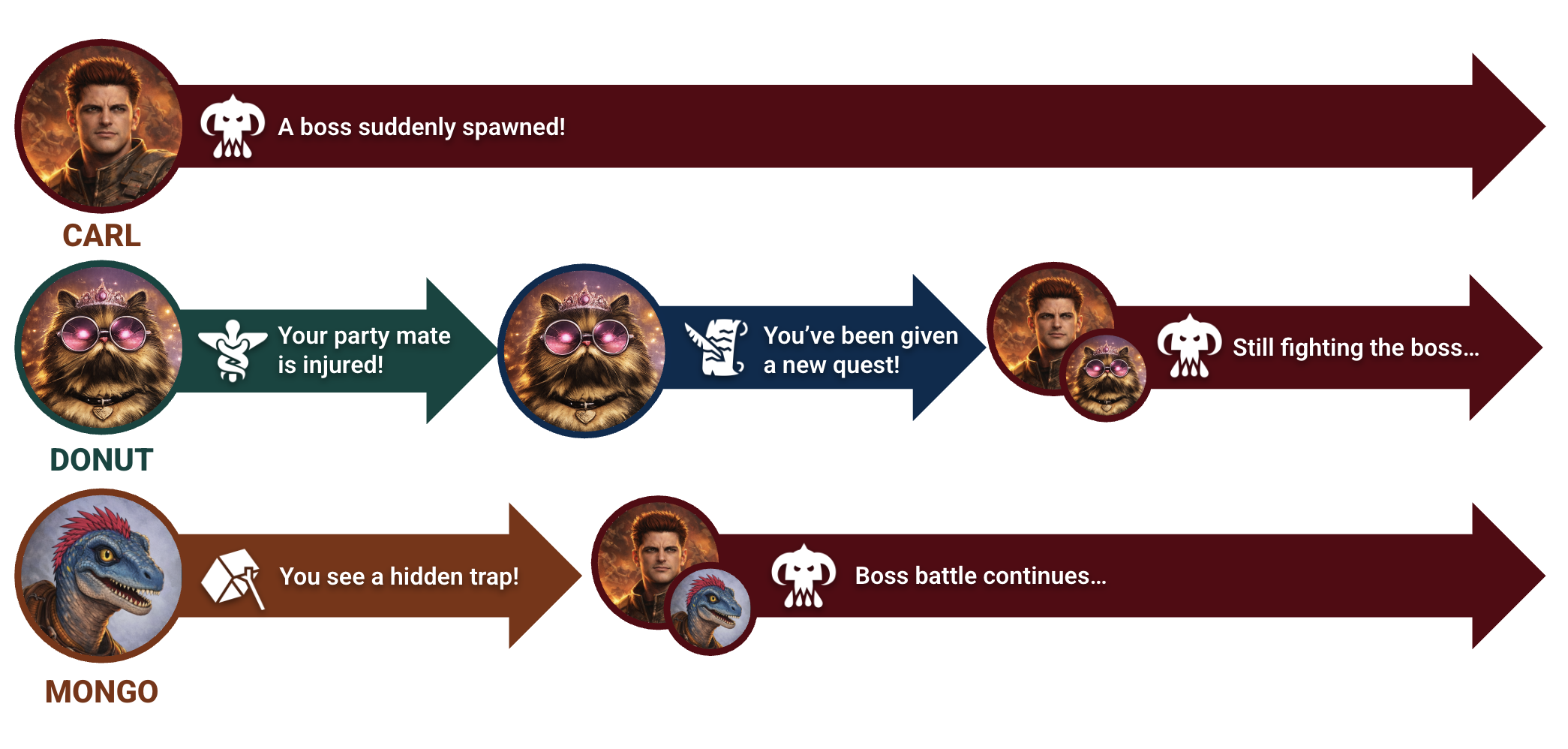
All the raw ability in the world means nothing if it's not well coordinated. Kafka also faces this same challenge.
At smaller scales, you can typically handle this by just throwing a few consumers at a topic and "figuring it out". Things will typically just work. As your scale grows however, it's possible for consumers to get overloaded (while others sit idle), which can start to cascade into other problems (e.g., rebalancing, retries, etc.)
In Kafka terms, each crawler is a consumer, and the dungeon’s chaos is chopped into partitions and handed out whether they’re ready or not. Once those hallways are assigned, each crawler is largely on their own — for better or worse.
Historically, teams tried to bridge this gap by treating consumer groups like work queues. They layered on manual commits, retry topics, dead-letter queues, and custom monitoring. With enough care, you could build something reliable — but only at the cost of growing complexity.
Living in that trade-off is exactly why Kafka Queues exist.
KIP-932 formalizes what teams were already trying to do. They transform that "someone should deal with this problem" to "someone is dealing with this problem". This makes ownership much more explicit and can help introduce visibility to things like backpressure, as well as making failures potentially less mysterious.
In dungeon terms, it’s the difference between a party frantically yelling "did anyone get that?" with their life on the line and one where everyone knows exactly what they’re responsible for.
Consumer Groups and Hope-Based Coordination
As mentioned earlier, before the introduction of Kafka Queues, most teams trying to build work queues on Kafka ended up using standard consumer groups and hoping for the best.
A consumer group divides partitions among consumers. Each consumer gets exclusive ownership of its partitions and processes messages in order. That’s great for streams.
It’s less great when each message represents independent work.
In dungeon terms, this is like assigning our friends Carl, Donut, and Mongo distinct hallways and telling them, "Anything that happens in your hallway is your problem."
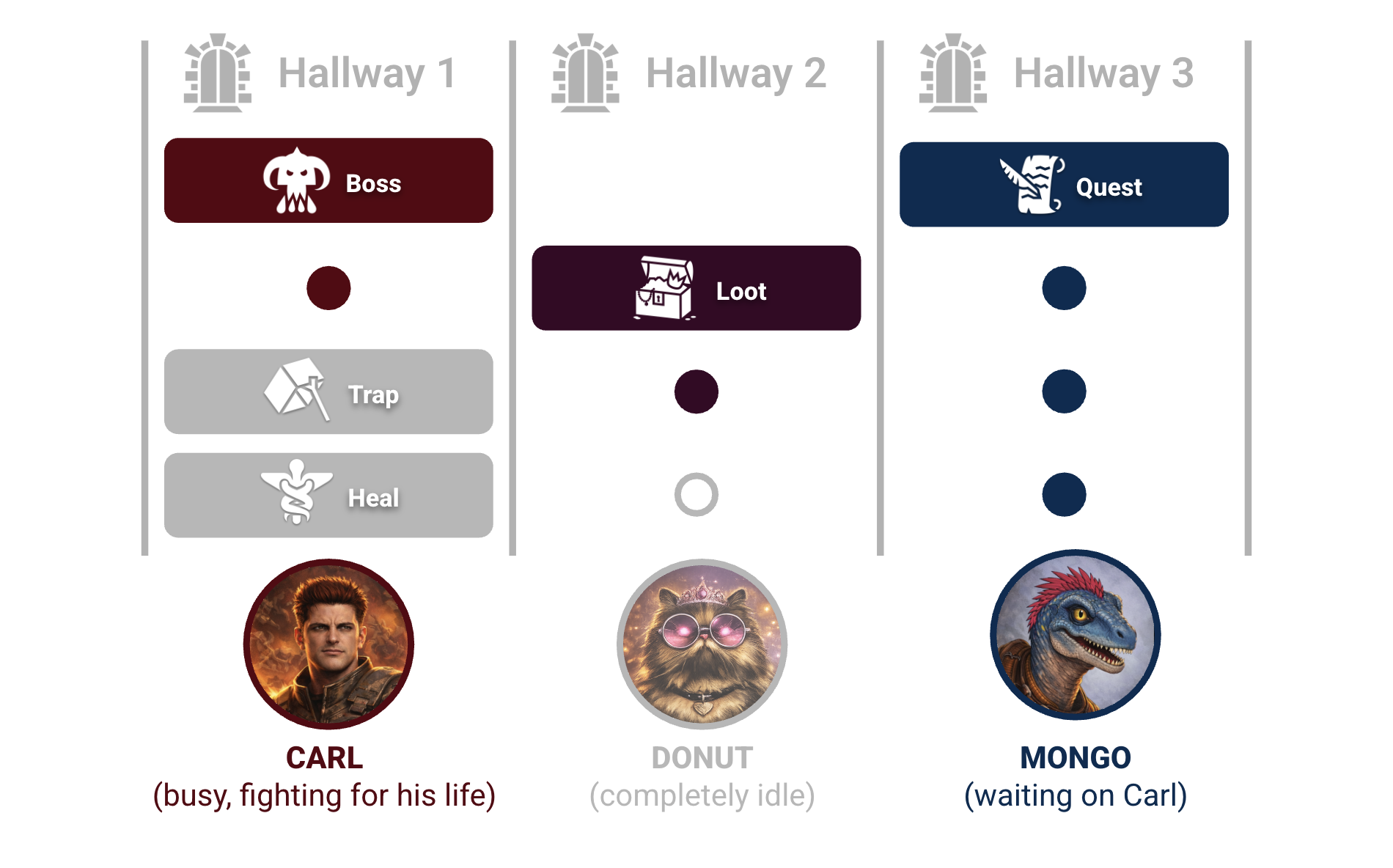
It mostly works — until it doesn’t ("Goddamnit Donut!").
In practice, it looks something like this:
while (true) {
val dungeonEvents = consumer.poll(Duration.ofSeconds(1))
for (event in dungeonEvents) {
/*
* This consumer represents a single hero in our dungeon (e.g.
* Carl). Other consumers in the group are his teammates or
* other dungeon crawlers trying to survive.
*
* In this consumer group model, Kafka assigns partitions to
* our heroes. Whatever events show up in *our* hallway becomes
* *our* responsibility — regardless of whether we're already
* overwhelmed, mid-fight, or even the wrong person to handle
* it.
*
* If it landed on this partition, it's our problem.
*/
process(event)
}
consumer.commitSync()
}A few problems show up quickly:
- Parallelism is limited by partitions, so you can’t easily add more “party members” to participate in the fight.
- Rebalances pause progress so when someone drops out, everyone has to stop and reshuffle responsibilities. In the middle of a fight, you probably die.
- Work gets unevenly distributed, as one long or difficult task can block progress while others sit idle (you don't want a Leeroy Jenkins situation).
Translated back to the dungeon: one party member gets sucked into an epic boss battle or overly dramatic side quest, while everyone else waits around organizing their inventories, wondering why nothing is happening.
To compensate, teams can often introduce things like manual commits, retry topics, dead-letter queues, and custom monitoring to make this behave like a real queue. It mostly worked — but only through convention and careful tuning.
Dungeon Crawler Carl is about surviving chaos.
Kafka Queues are about coordinating chaos.
Share groups are how Kafka finally does that.
Share Groups and the Art of Party Survival
Kafka Queues are built on a new coordination model called share groups.
A share group is a set of consumers that cooperate on a shared pool of work. Instead of owning partitions, members pull individual tasks, process them, and explicitly acknowledge completion.
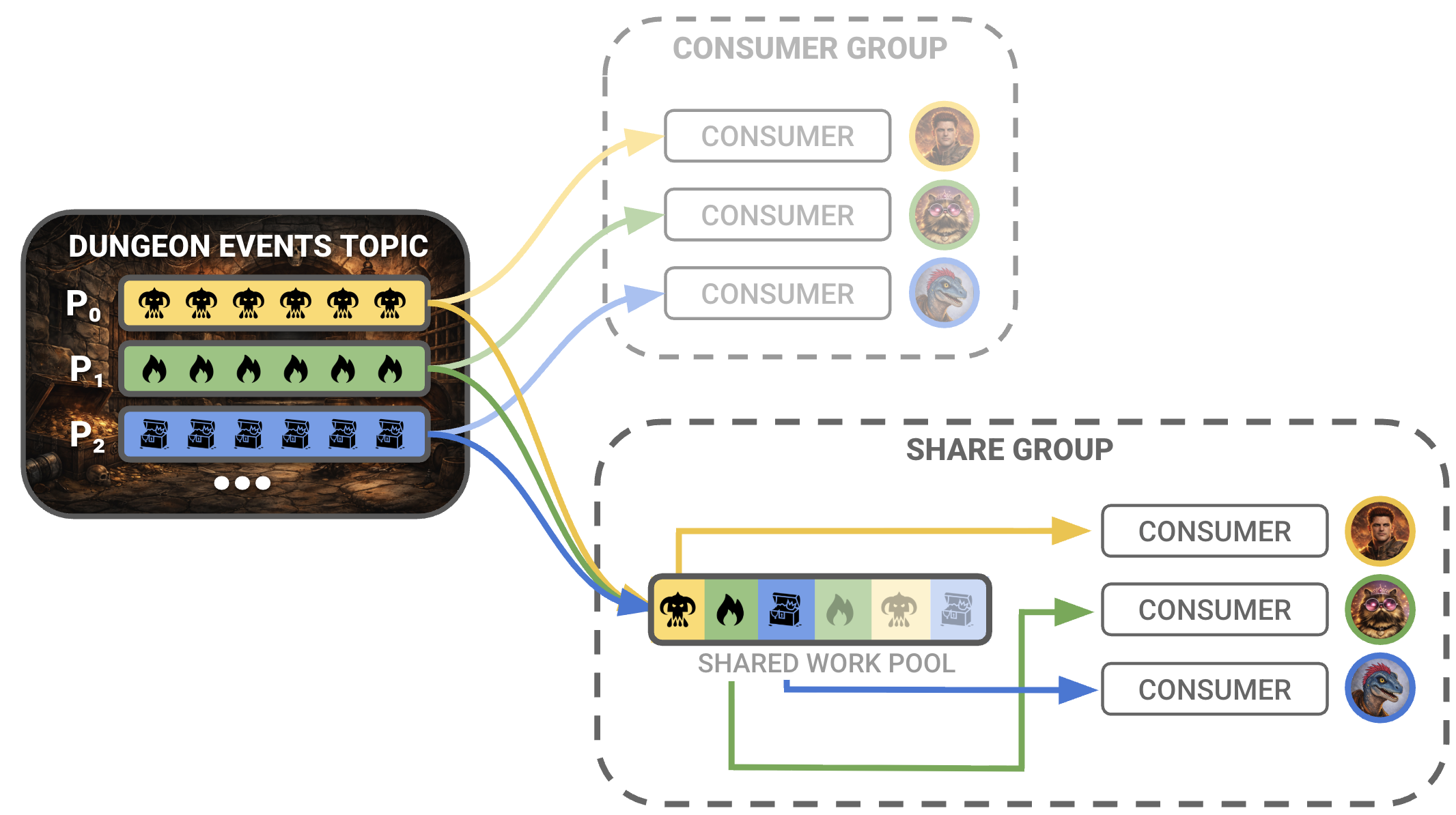
If that sounds familiar, it’s because it’s exactly how a dungeon party works.
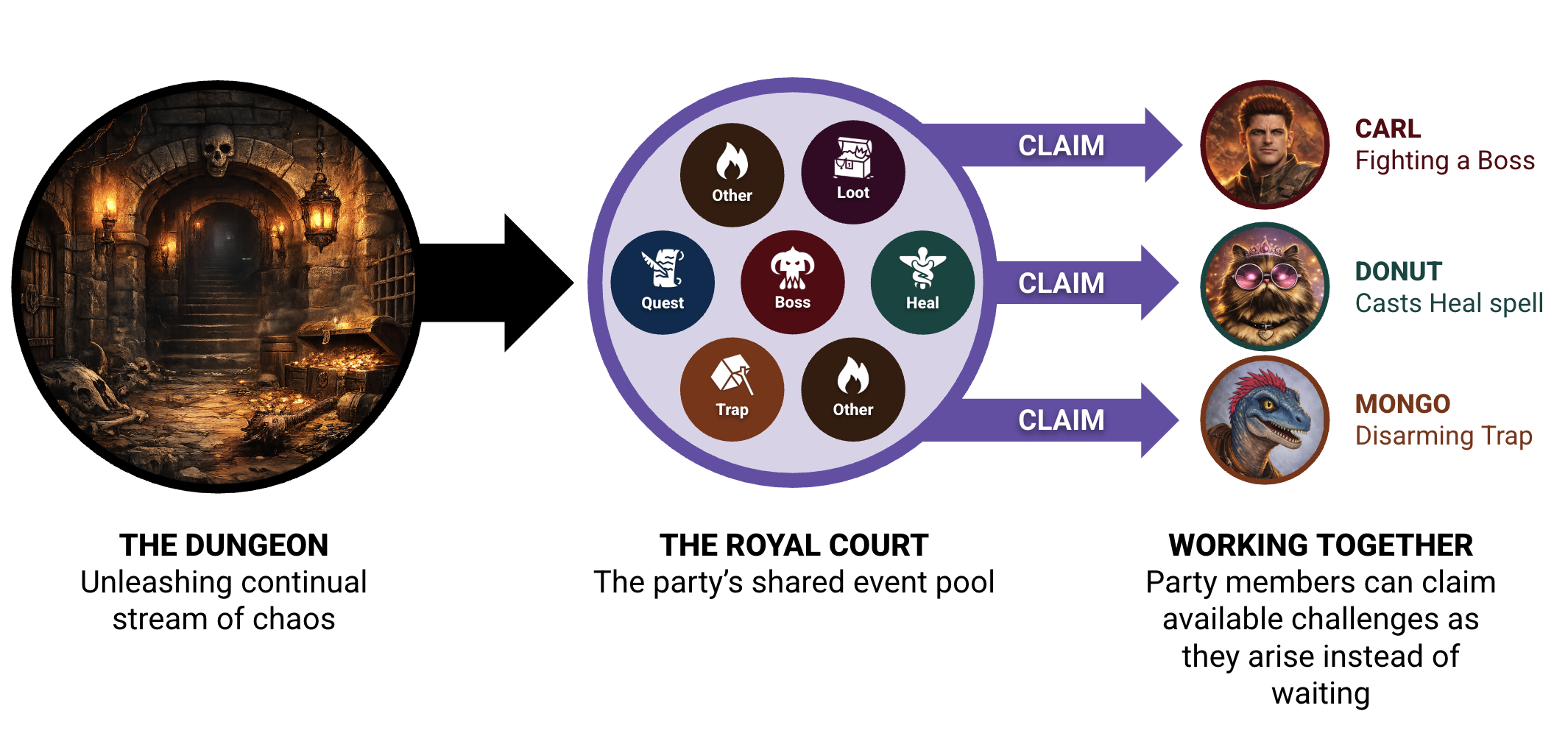
Everyone sees what’s happening. But individual members take ownership of specific problems. The dungeon throws outlandish scenarios, sudden threats, and impossible decisions at the group. Party members step up and take responsibility.
And if someone gets teleported away — or, you know, dies — before finishing their part, the work goes back into circulation.
Kafka finally has a native version of that model.
while (true) {
// Attempt to claim the next available task
val dungeonEvent = queue.receive()
/*
* This consumer still represents a single hero in the dungeon.
*
* The share group is the party and the queue is the stream of
* events taking place around our heroes.
*
* Work is assigned intentionally and accepted explicitly.
* Until this is acknowledged (or the lease expires),
* no one else will touch it.
*
* If we fail (or crash) mid-event (e.g., one of the heroes gets
* teleported away and can't do the task), the event goes back
* back into circulation for another party member to finish.
*/
process(dungeonEvent)
queue.ack(dungeonEvent)
}With share groups, several things fundamentally change:
- Explicit assignment instead of implicit ownership
Work is claimed through leases, not inherited through partitions. Until a task is completed or expires, no one else touches it. Party members are no longer just reacting to the first thing they see, they can be more intentional and focus on what's important. - Natural backpressure
Busy consumers stop pulling work, while idle ones pick up more. Overloaded ones fall out of rotation without any kind of special tuning — just as a wounded party member (hopefully) stops charging into a new battle. - Flexible scaling
Parallelism is no longer tied to partition count. Workers scale with demand, not topology. Reinforcements can join without redesigning the dungeon. - Built-in failure recovery
Crashes or failures release leases so any unfinished work returns to the pool. Retries are part of the protocol — if a party member gets teleported away mid-quest, someone else can pick up where they left off. - A simpler processing model
Instead ofpoll → process → commit, consumers followreceive → process → acknowledge. Work is claimed, completed, and released — like taking on a quest, finishing it, and reporting back.
There's no more shouting "did anyone get that?", accidental heroics, or folks just standing in silence as the world around them is on fire.
It’s what a real party looks like and a real party is one that doesn't just survive, they thrive.
Begin Your Own Queuing Adventure
If you’re interested in trying or playing around with Kafka Queues, start simple.
They seem like they would shine when messages represents independent work (e.g., background jobs, enrichment tasks, alert processing, report generation, or long-running workflows). If you need strict ordering, then your traditional streams are still likely the better fit.
Kafka Queues were introduced as an Early Access feature in the 4.0 release of Kafka in March 2025. While the model is very promising, support may not yet be there for many scenarios (e.g., DLQs, exactly-once guarantees, and certain recovery patterns). Tread carefully before relying on them in production or mission-critical systems.
If you’d like to go deeper or learn more about Kafka Queues, I'd highly recommend checking out any/all of the following "strategy guides":
- KIP-932: Kafka Queues and Share Groups - The official proposal and design document for the feature, with extensive technical detail.
- Queues for Kafka - A detailed post from the author of KIP-932, Andrew Schofield, covering motivations, design, and common questions.
- Let's Take a Look At Queues for Kafka - Gunnar Morling provides a great breakdown of practical behavior, including retries and persistence.
- Queues for Kafka Explained (Video) - Confluent Developer Advocate Sandon Jacobs provides an incredible breakdown and walkthrough of the feature.
Best of luck in the dungeons — and in production!