
Exploring Squirrelly Apache Flink Performance Issues through Continual AI-Driven Evaluation

Last month, I wrote up a blog post discussing a three-phase cycle (profile, analyze, improve) for leveraging LLMs and other AI tooling to evaluate Apache Flink jobs for potential performance improvements. This post goes through what that process might look like in a more automated fashion to help you track down those often squirrelly issues hidden within your Apache Flink jobs that could be holding your pipeline back.
Introducing Squirrelly
In a simple proof-of-concept, which I'm calling Squirrelly, I walk through this process which automates the process by running a profiler instance against a job deployed in Kubernetes, capturing the appropriate profiler artifacts and providing those to an external LLM for analysis.
The overall concept is fairly simple – Squirrelly will run within your Kubernetes cluster either as an an ad-hoc, one-off job (or potentially as an automated cron job that would periodically issue the analysis requests).
What's Squirrelly Doing?
As mentioned in the beginning of this article I mentioned a three-phase cycle that I've used in the past to analyze Apache Flink jobs by feeding profiler results and potential code context into an LLM for analysis. This process was always done as a manually process – this is just taking that same concept and taking more of the legwork out of it.
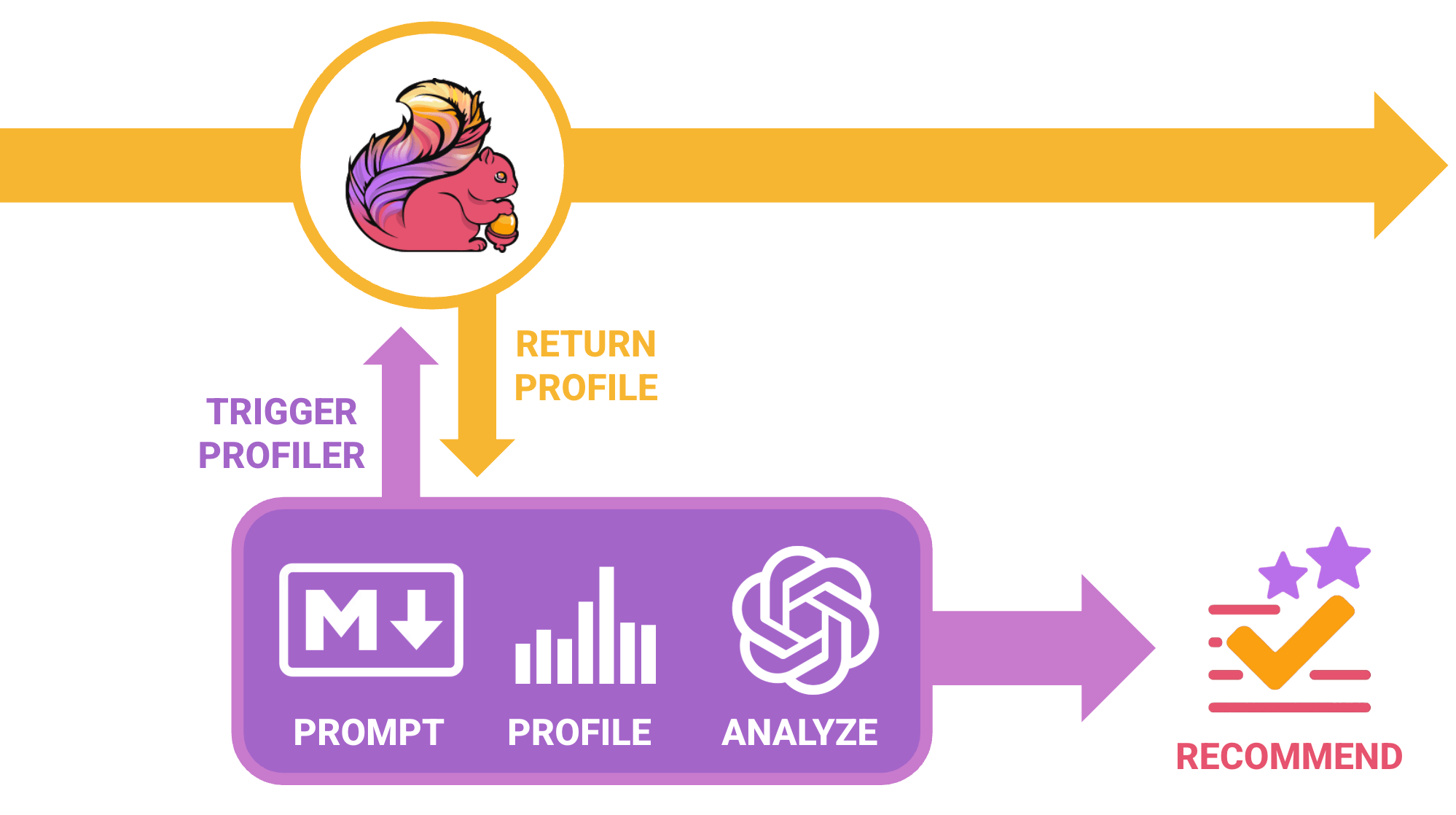
In this concept, you'd just point Squirrelly to an existing Flink job that's running an it will do the following:
- Issue a specific type of profiling request via the built-in Apache Flink Profiler via its exposed REST API endpoint (you can configure the duration and type of profile used)
- This assumes that the job has profiling enabled via the
rest.profiling.enabledconfiguration.
- This assumes that the job has profiling enabled via the
- After the profiler has completed, the service will gather the generated artifact and prepare a request to a given LLM for analysis. The request itself will include the following:
- The generated HTML-based flame graph that was gathered during the previous profiling run.
- A user-defined Markdown prompt to help frame the context to the LLM (completely configurable and baked in by default).
- An optional series of one or more artifacts that can be provided to the LLM to define context and create associations between the code that was executed.
- Once this analysis process is completed, it will log out the recommendations provided that you can begin to take action on.
Let's See It in Action
We can easily demonstrate this by creating a sample, intentionally poor performing Apache Flink job and running it within a local environment (via minikube, etc.)
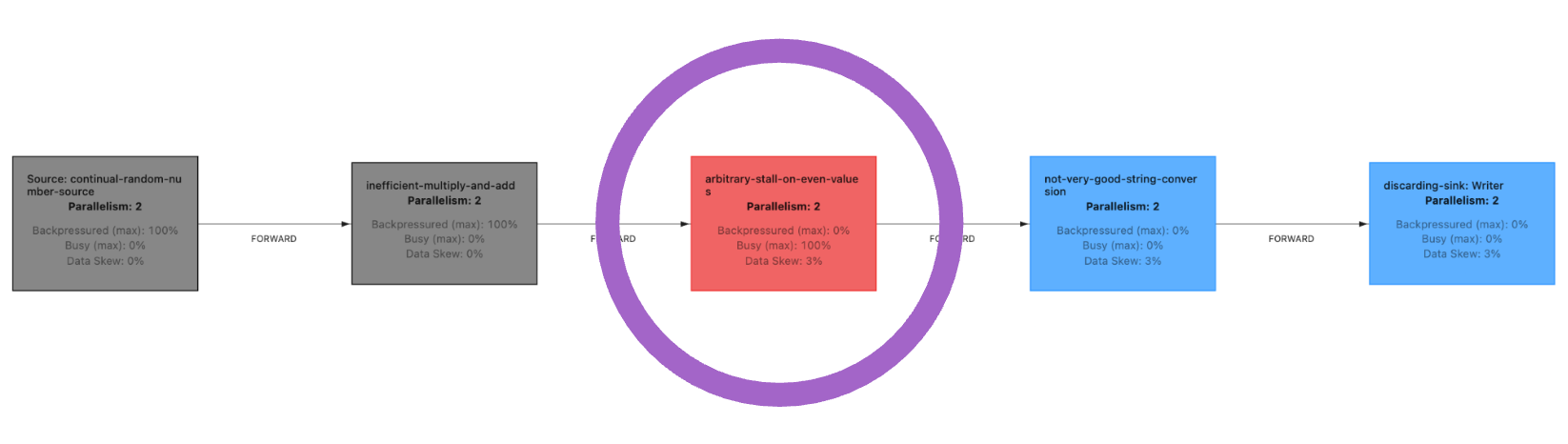
Thread.sleep() call) highlighted with the large purple circleWith that job running, we can configure Squirrelly to point to that job and issue a request to the REST API to trigger a profiler run:
./scripts/run-profiler.shAnd what we'll find is that it successfully captures the generated artifact and then issues a submission to the configured service (in this case it uses the OpenAI API):
🔬 Squirrelly Profiler
==================================
Target FlinkDeployment: sample-job
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
📊 Processing FlinkDeployment: sample-job
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
✅ JobManager Pod: sample-job-548bffcd7-b2vb6
🔍 Fetching job information...
✅ Found running job: 49a1dfd3890613125656bf07dd2c52ed
🔍 Fetching job details to find vertices...
✅ Vertex ID: bc764cd8ddf7a0cff126f51c16239658
🔬 Triggering Flink Profiler...
✅ Profiler triggered successfully
⏳ Waiting 60 seconds for profiler to complete...
📦 Checking for profiler artifacts on TaskManager pods...
✅ Found profiler artifact!
🎯 Artifact for this run:
...
✅ Profiler completed successfully! Artifacts generated.
📤 Submitting artifact for analysis...
📊 Artifact size: 28404 bytes
✅ Artifact copied successfully (28404 bytes verified)
🔨 Building JSON payload...
✅ JSON payload verified (30897 bytes, contains artifact marker)
📡 Sending request to OpenAI API...
HTTP Status Code: 200
✅ Analysis request submitted successfullyAfter analysis is completed, we'll see the recommendations defined in the log, although you could potentially change things around and write this to cloud storage, email, etc:
Analyzing flame graphs is a detailed task that requires careful examination
of the profiling data. Here's an analysis of the provided Apache Flink job's
performance based on the flame graph content you shared:
Key Bottlenecks (Ranked)
------------------------
Bottleneck 1: User Function - EvenStallingFunction.map()
- Where it is:
dev/squirrelly/SimpleFlinkJob$EvenStallingFunction.map
- How large it appears:
Approximately 2% of the total samples.
- Why it matters:
This UDF plays a significant role in your Flink job and shows
noticeable CPU impact. It may contain expensive operations or waiting
behavior that affects throughput.
Bottleneck 2: Thread Sleep
- Where it is: java/lang/Thread.sleep
- How large it appears:
Appears multiple times, each contributing roughly 2–3% of samples.
- Why it matters:
Frequent use of Thread.sleep may indicate inefficient waiting or
deliberate delays, both of which reduce processing speed.
Bottleneck 3: Record Writer Flush
- Where it is:
org/apache/flink/runtime/io/network/api/writer/
RecordWriter$OutputFlusher.run
- How large it appears:
Roughly 11% of the samples.
- Why it matters:
Frequent flushing introduces latency and reduces throughput, especially
if buffer management is not tuned for the workload.
2. Root Causes
--------------
Bottleneck 1: Inefficient UDF Logic
- Cause:
EvenStallingFunction.map may include unnecessary computation or complex
transformations that slow down processing.
Bottleneck 2: Inefficient Waiting Strategy
- Cause:
Thread.sleep may be creating artificial delays caused by misconfigured
timeouts or inefficient backpressure handling.
Bottleneck 3: Frequent Flushing
- Cause:
RecordWriter may be flushing too aggressively or using suboptimal
configuration, resulting in excessive I/O activity.
3. Actionable Recommendations (Ranked)
--------------------------------------
Recommendation 1: Optimize User Function Logic
- Proposed change:
Refactor EvenStallingFunction.map to reduce computational overhead and
eliminate redundant operations.
- Why it helps:
Reducing CPU usage within the UDF directly improves throughput and
lowers resource consumption.
- Impact estimate: High
- Trade-offs:
Ensure that functional correctness is preserved during refactoring.
Recommendation 2: Review Sleep Calls
- Proposed change:
Reduce or eliminate Thread.sleep. Prefer Flink backpressure and timeout
mechanisms instead of manual sleeping.
- Why it helps:
Removing intentional delays results in faster, more responsive job
behavior and higher throughput.
- Impact estimate: Medium
- Trade-offs:
Timing and synchronization logic must be handled carefully.
Recommendation 3: Adjust Buffer Flushing Configuration
- Proposed change:
Tune buffer sizes or flush intervals to reduce how frequently data is
flushed.
- Why it helps:
Less frequent flushing lowers I/O overhead and can significantly improve
throughput.
- Impact estimate: Medium
- Trade-offs:
Larger buffers may increase memory usage, so monitor accordingly.
4. Additional Observations
--------------------------
- Mailbox Processing:
MailboxProcessor activity is visible and may become a bottleneck under
higher message rates. Monitor as the workload scales.
- GC Pressure:
Be mindful of unnecessary object creation in UDFs or operators, as this
can increase GC activity and slow processing during heavy load.
This analysis provides a solid baseline for optimizing the Flink job based
on the profiling data. Further iteration and measurement will help refine
performance improvements.
It obviously goes without saying but...

Give It a Whirl
As mentioned earlier in the post – this is really just a proof-of-concept, but I've created a sample GitHub project that show it in action. It leverages Kubernetes, Docker, a sample Flink job, and a series of scripts to demonstrate the process.
If you have the prerequisites installed (e.g., Java 21, minikube, Docker, Maven, Helm, etc.), you should be able to just go through the following steps:
# Clone down the repo
git clone http://github.com/rionmonster/squirrelly.git
cd squirrelly
# Deploy everything
./scripts/deploy.sh
# Run the profiler (see README for all available options)
./scripts/run-profiler.shSince this example uses the OpenAI API, you must have a OPENAI_API_KEY environmental variable set for all of the pieces of this puzzle to work. (e.g., export OPENAI_API_KEY="secret-secret').
Things simply won't work (on the analysis front) if you can't communicate with your preferred AI provider.
What's Next?
Who knows really? This was really just playing around with automating a process to streamline analysis for existing Flink jobs that are running in Kubernetes. The entire codebase is openly available on GitHub, so if you have a specific use-case, want to extend it for your own purposes, or just play around – fire away!
A few improvements that immediately come to mind would be:
- Continuous Evaluation / Cronjob - Extend the ad-hoc profiler to an ad-hoc service or CronJob that would periodically run these types of operations automatically (without user intervention at all).
- Additional AI Provider Support - Add support for additional openly available LLMs and their respective APIs for analysis besides just OpenAI.
- Metrics & Code Context - Potentially incorporating ways to extend the prompt with real-time values (e.g., inject specific currently available metric values into the prompts to assist with context, actual source files/source maps to extend context).